Q3'25: Show Me the Money

By: Jack Schibli
As a reminder, this blog is an outlet for our thoughts, primarily on the macroeconomic environment, which contextualizes our investments. Please subscribe via the form at the bottom of the page to receive future post notifications.
If you are interested in learning more about our investment strategies, please kindly fill out our contact form here.
A little over a year ago, we wrote a piece on Artificial Intelligence (AI). We explored the possibilities of “Artificial Superintelligence” (ASI), the global race for which is driving a once in a lifetime capital investment cycle. We then dared to ask what might be required for these investments to generate a return. Today, capital spending has continued unabated, with financing sources migrating from cash flows to debt and circular equity transactions reminiscent of dot-com behavior, while return on investment remains an afterthought. We will update our thoughts on AI’s technological progress, key assumptions underlying its development, and later, what it means for markets and the economy.
We may sound like mighty AI bears, as we are highly critical of the ability for this capital investment cycle to generate adequate returns for those companies building and supplying the infrastructure. Nevertheless, the buildout is forging ahead, which will mean more widespread access and dramatically lower costs for consumers and businesses utilizing AI. In other words, we foresee AI beneficiaries shifting from solely pick-and-shovel providers to nearly every business in the world, an idea the market appears to lend very little credence to.
TLDR: – "too long; didn’t read." We recognize our posts can be lengthy and challenging to digest, so here’s our executive summary:
- The U.S. equity markets, and by extension the U.S. economy, are now heavily dependent on AI delivering a real return on investment (ROI).
- The race toward superintelligence has kicked off an unprecedented capital spending cycle on AI data centers. In our view, propelled by FOMO rather than unit economics analysis.
- Uncertainty around future model progress, tech stack innovations, open source vs. closed source, GPU useful life assumptions, and more widen the possible distribution of ROI outcomes.
- As with past booms, investors appear to be making the cardinal sin of mistaking the cyclical for the secular, leading to peak earnings multiples paid on peak-cycle earnings.
- The reversal of which we believe is likely to cause a material downturn in AI infrastructure companies, which now make up nearly half the S&P 500.
- For now, the buildout is full steam ahead. Barring any black swan developments, we expect this can continue until capital becomes skeptical, or poor ROI comes to fruition.
- Like the dot-com era, we believe an eventual glut of compute will result in cheap and abundant access to AI, offering material benefits to businesses and consumers.
Put it all on Black 🎰
The single greatest driver of AI capital spending is the belief that scaling laws will continue to hold. Scaling laws describe a power-law relationship between an AI model’s performance and its inputs (number of parameters, amount of training data, and the computational resources used to train it). In other words, the power law states that linear improvements in performance are achieved through exponential increases in computing power. Read that sentence again, because it describes diminishing performance returns for exponential increases in resources.
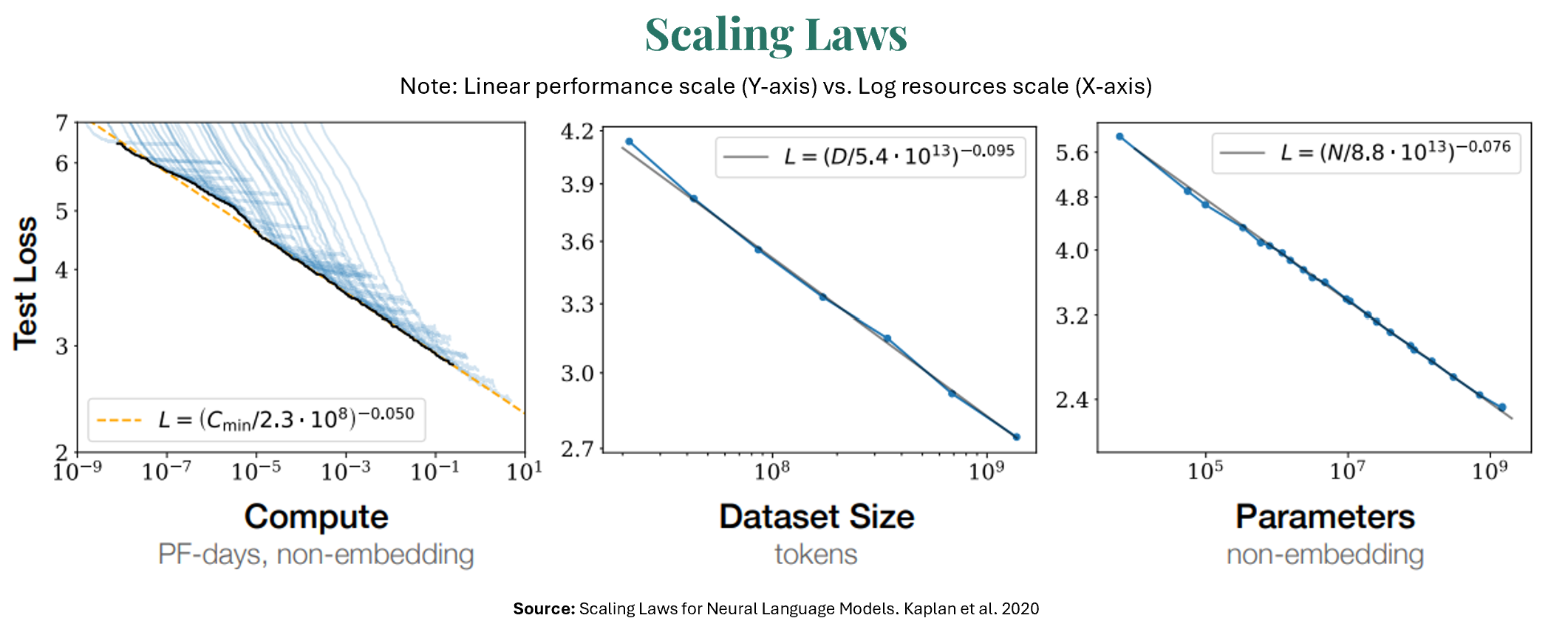 For Illustrative Purposes Only
For Illustrative Purposes OnlyConsider that each generation of OpenAI’s GPT model has utilized ~70x as much compute as the previous version (GPT-2=4e21 FLOP, GPT-3=3e23 FLOP, GPT-4=2e25 FLOP). Industry wide, Epoch AI estimates that training compute power has grown 5x per year, while algorithmic improvements have reduced physical compute needs for the same level of performance by 3x. This means effective computational power is growing approximately 15x per year. These exponential advances mean we are approaching very large numbers for the next generation of models in terms of computing power, energy use, and subsequently cost. It’s also important to recognize the lag between new data center development announcements and model training. For example, ChatGPT-5, launched in 2025, was likely trained in early 2024 – a lifetime ago in the context of this AI craze. Similarly, today’s monstrous data center announcements will take 12-36 months to build, then another 6-8 months to train the model, and another 6-8 months before public release. Thus, today’s spending will manifest in models released in 2028.
Interestingly, OpenAI’s most recent model, ChatGPT-5, was widely seen as underwhelming, as model improvements exhibited the diminishing returns from the pre-training runs that the power law predicts. Instead, performance gains have largely come from post-training techniques. First, through what’s called reinforcement learning (RL), the model further learns through trial-and-error interaction with the human environment. Secondly, through Chain-of-Thought (CoT) reasoning, which enables the LLM to break down a question into smaller intermediate steps before answering. Oxford researcher Toby Ord finds that between 63% and 93% of the performance gain from RL/CoT comes from CoT inference scaling. Logically, giving the model greater access to compute at the time of inference (i.e. user request) should improve performance; however, this comes at a great cost. Pre-training and initial RL done post-training are both single occurrences, in other words, an expense that can be capitalized, but CoT reasoning is done with each response (an OpEx line item), so scaling this compute 10x would result in 10x the cost of each inference request – that’s a problem for frontier labs.
If pre-training scaling laws are plateauing and scaling shifts to inference, this has meaningful implications for business models and the return on investment equation. For example, consider a datacenter of GPUs used to train an LLM. Previously, following training, these GPUs could be repurposed to serve millions (estimate per CEO of Anthropic) of model copies to users in the inference stage. However, if inference compute is scaled 10x, then the number of model copies being served by the same cluster of GPUs also falls by a factor of 10. Not only has the cost to serve just risen tenfold, but the number of users being served has fallen by 90%. This is simultaneously a cost and a revenue problem unless the cost for a user to access this model rises 10x. Meanwhile, users saying “Please” and “Thank you” in their chats is costing labs tens of millions of dollars.
Perhaps it should come as no surprise that big tech companies are plowing seemingly every last dollar into building AI data centers to exponentially increase computing power. For those who believe (worship?) the scaling law, why not skip a generation and plan to 100x compute instead of 10x? This appears to be OpenAI CEO Sam Altman’s plan. In an internal memo leaked last month, Altman unveiled a roadmap to build 250 gigawatts (GW) of AI data center capacity by 2033. A couple of important reference points: 1) OpenAI data center capacity is expected to be 2GW by the end of this year 2) 250GW is equivalent to 25% of the current U.S. installed power generation 3) the current cost to build a 1GW AI data center (per NVDA CEO Jensen Huang) is upwards of $60 billion, making Altman’s vision a roughly $15 trillion endeavor or 50% of current U.S. GDP!
For Altman, it’s go big or go home, as he doesn’t have the same resources as today’s multi-trillion-dollar tech giants. We believe he is capitalizing on his moment in the spotlight to make an all or nothing bet on leapfrogging the competition. Altman’s evangelism for superintelligence has indoctrinated not just Silicon Valley but many prominent tech CEOs, investors, and even global sovereign leaders. Ironically, he was among the first to call AI a bubble back in August before going on to blow it even bigger – we hope Michael Lewis catches that detail for The Big Short 2.0. In the last month, OpenAI has announced a series of prolific and peculiar transactions totaling 26GW of capacity. As you can see below, many of these “partnerships” appear to be circular in nature. These announcements equate to an estimated $1.5 trillion in commitments, which, for a loss-making company with $13 billion in revenue, is pure fantasy to put it mildly.
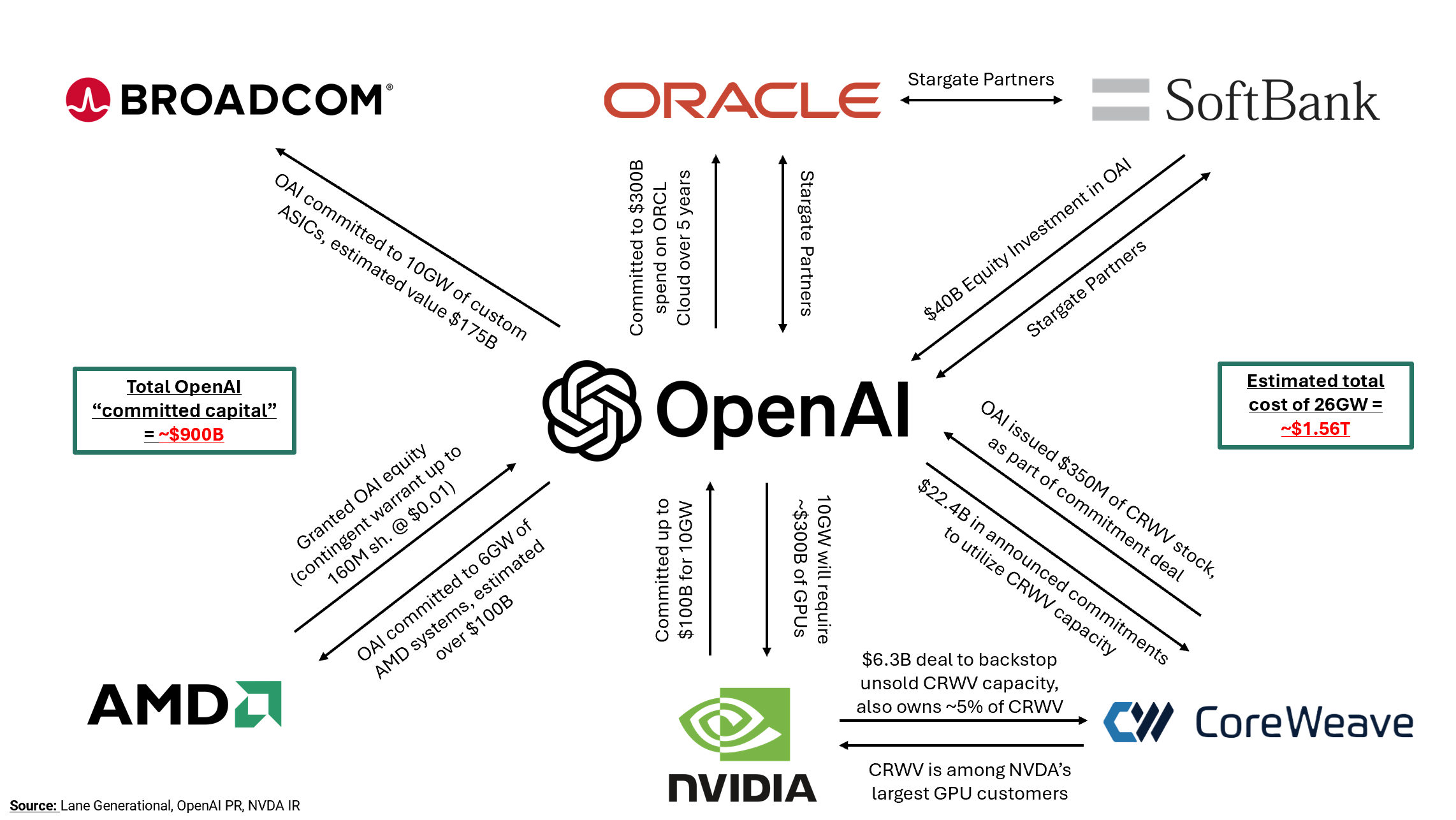 For Illustrative Purposes Only
For Illustrative Purposes OnlyDuring the dot-com bubble, companies such as Lucent and Nortel extended billions in vendor financing to customers, subsequently booked as revenue. Nvidia appears to be following a similar strategy by funding its customers (e.g., OpenAI and Coreweave) with equity, allowing them to turn around and purchase GPUs. It appears an “infinite money glitch” – let’s say Nvidia gives $20B in funding to a customer, who then uses it to purchase $20B of Nvidia GPUs. This $20B is worth approximately $10B in net income to Nvidia, and the market is valuing forward earnings at a round 30x, hence the market cap of Nvidia appreciates by roughly $300B, all from just $20B in funding – magic! Weeks later, it has been reported that Nvidia is in discussions to guarantee OpenAI loans, possibly using Nvidia’s equity as collateral. Every company "blessed" by an OpenAI partnership saw its shares jump materially on the day of the announcement, cumulatively totaling $800 billion in single day gains.
Now, to the trillion-dollar question – what’s required to make a return on AI capital investment? We use the announced 26 GW from OpenAI (estimated total cost of $1.56 trillion from 2026-2030) as well as hyperscaler CapEx estimates to arrive at roughly $730 billion of investment in 2026 (up from ~$400 billion in 2025) and set to grow further in 2027 and beyond. We assume that each dollar of CapEx carries 15 cents of depreciation per year (50% spent on chips depreciating over five years, and 50% spent on the rest of the data center depreciating over ten years), 5 cents of operating cost per year, and 10 cents of cost of capital (10% per year). Thus, each $1 invested requires $1.30 over five years to break even. Conservatively using $730B as the average annual spend for the buildout (2026-2030), that would mean to break even AI revenues would need to be $4.7 trillion by 2035 cumulatively. If we use Bain’s estimate of 4x for a “sustainable” revenue to CapEx ratio, rather than just bare minimum payback with zero profit, the cumulative number jumps to $14.6 trillion. If we assume revenues are distributed evenly over the 2027-2035 period, we get $520 billion of annual revenue for breakeven and $1.6 trillion using Bain’s sustainable breakeven ratio.
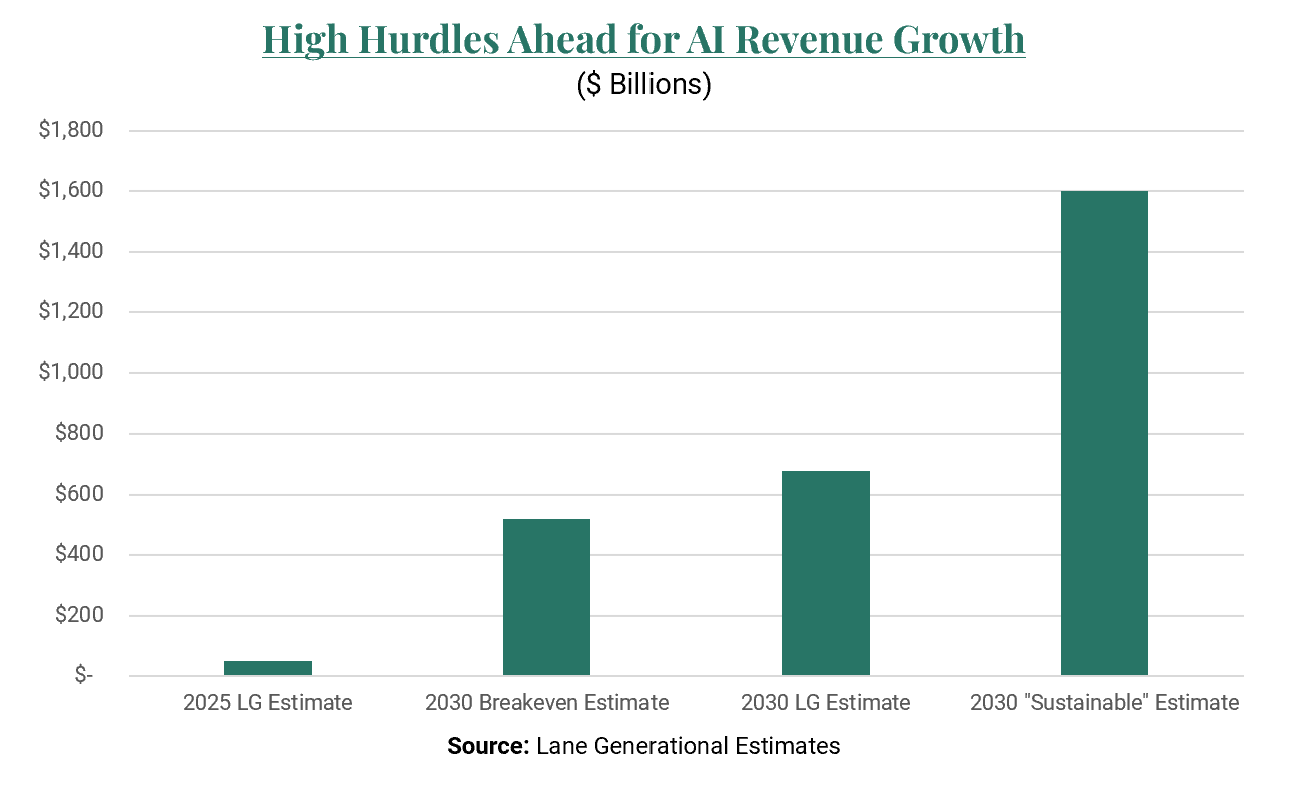 For Illustrative Purposes Only
For Illustrative Purposes OnlyWhile it’s nearly impossible to approximate AI revenue potential, as much depends on the technology’s ability to further improve, which would allow it to ascend the corporate ladder from an assistive tool to a full-fledged entry-level role, to a mid-level manager. We estimate six core revenue buckets: 1) knowledge worker labor displacement (AI agents), 2) physical labor displacement (robotics), 3) software displacement, 4) R&D displacement, 5) e-commerce take rate, and 6) consumer-facing LLM. We arrive at a total estimate of $677 billion in revenue in 2030 (roughly in line with our breakeven estimate), with some aggressive assumptions, but limit our estimates (except consumer LLM) to the U.S. market. Most assuredly, our estimates are incorrect and are certainly missing new revenue buckets to come. Yet, the objective of the exercise is to show that just breaking even is a very high hurdle. Our assumptions imply almost 30M American jobs displaced, half of the software industry that’s taken 25 years to build, displaced in less than 10 years, a quarter of the entire U.S. R&D market, 1 in 4 online purchases taking place through an LLM, and 3 billion people using an LLM worldwide with 600 million paying for premium access – all rather optimistic we feel and arguably double counting.
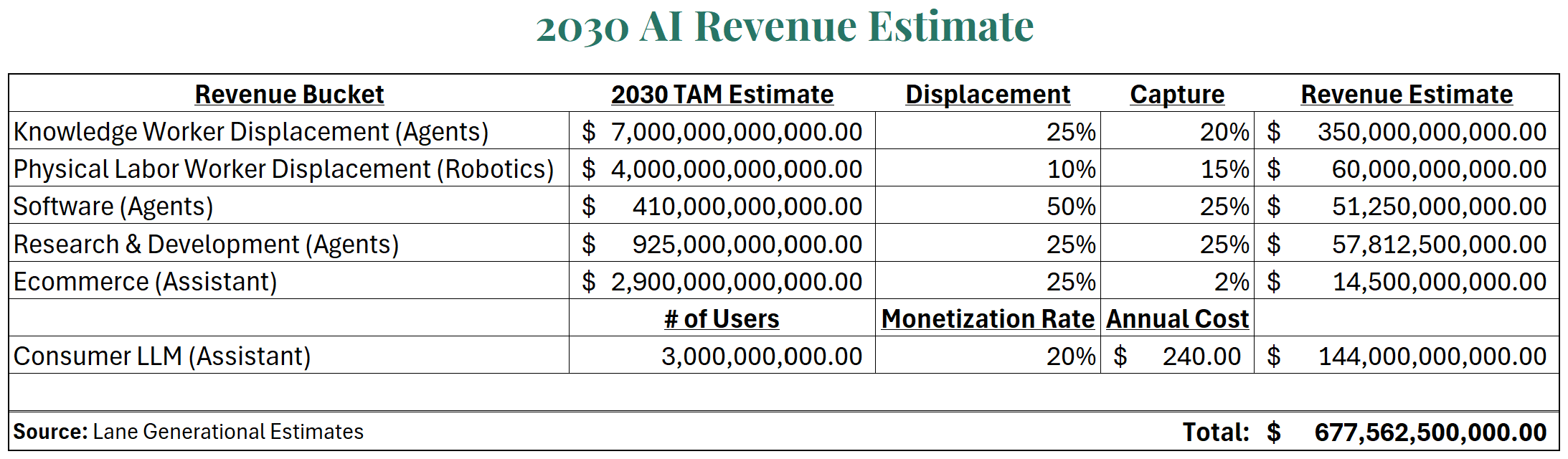 For Illustrative Purposes Only
For Illustrative Purposes Only
Dangerous Assumptions ☢️
Amidst the enthusiasm, there has been a void of serious consideration for return on investment. Most seem to subscribe to Mark Zuckerberg’s view: “if we end up misspending a couple hundred billion dollars, that’s going to be very unfortunate, but I would say the risk is higher on the other side.” In other words, FOMO – fear of missing out – usually not a strong foundation for an investment thesis, but a strong momentum propellant inside bubbles. As we previously outlined, much of the hope for success hinges on scaling laws holding true for the next few generations of models; however, we believe there are several other dynamic factors that investors are not adequately contemplating.
One of these factors is the useful life assumption for AI chips (GPUs), after all, these are chips, not railroads! Today, the hyperscalers (AMZN, GOOG, META, MSFT, ORCL) use an average useful life of six years for accounting purposes. This estimate has risen over the last five years but is now showing signs of reversal, as Amazon recently decreased its estimate from six years to five years for “certain AI chips.” We expect others to follow suit, and the key reason is that GPUs, which are relatively new to these hyperscalers, have far shorter useful lives than their CPU counterparts due to higher-intensity workloads. GPU lifespans will vary depending on utilization rates, but an internal Google employee was cited saying that at typical utilization rates of 60-70%, a GPU will typically survive one to two years, and three years a most. This would more than double the depreciation costs and halve the available timespan in which to generate a return, not to mention it would require a significant increase in CapEx every few years to replace the fleet of GPUs, all of which would materially impact the ROI equation.
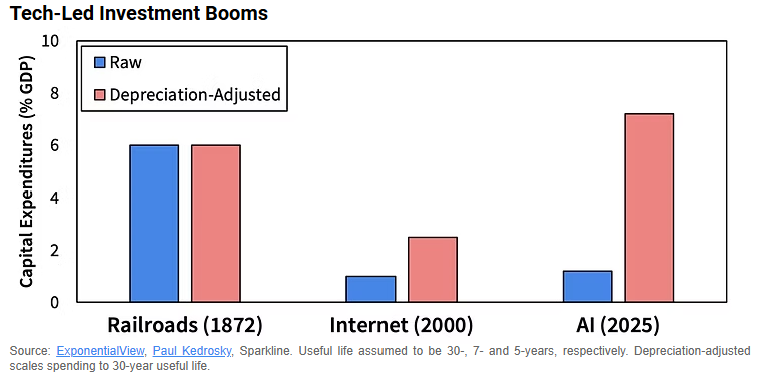 For Illustrative Purposes Only
For Illustrative Purposes OnlyNext, we fear the investment cycle is not considering the possibility of dramatic improvements in technological efficiency that could result in a large disconnect between current future capacity expectations and reality. Efficiency improvements are coming at the chip, algorithmic, and system levels. For example, Nvidia’s Blackwell chip shows a 10x increase in tokens (compute) per watt compared to the prior Hopper generation. This renders any data center running Hopper chips at a major competitive disadvantage, and these were released just three years apart, further emphasizing the shortened practical lifespan of a GPU. In China, where access to cutting-edge chips is limited for geopolitical reasons, companies are finding new efficiency breakthroughs. Alibaba recently announced an 82% reduction in the number of GPUs required to serve LLM inference via a novel system that virtualizes GPU access at the token level, as opposed to the GPU level, allowing a single GPU to serve multiple models simultaneously. Lastly, there is this paper, which utilizes analog in-memory computing (IMC) to implement the attention mechanism in transformers. This approach significantly reduces data movement between memory and the processors by storing token projections (memory) in the same place as processing. Consequently, it reduces energy consumption by 10,000x and latency by 100x. While only a small-scale experiment, advances like these directly tackle bottlenecks such as power and memory, pointing to a future where edge devices (phones, laptops) are capable of powerful inference, to the point where calling data centers may not be necessary for many everyday inference requests.
DeepSeek, a Chinese AI lab, shocked the world earlier this year with the release of DeepSeek R1, an LLM that rivaled U.S. frontier models but was developed at a fraction of the cost (and with a fraction of the compute). The entire complex of AI stocks nosedived in response, but the panic has long since been forgotten. In our view, the true threat of DeepSeek was its open-sourced nature. Taking a step back, the model training process simply produces a set of weights (numerical parameters that determine the importance of features in the dataset), which define the behavior of a model. Open sourcing is to make these weights (and therefore the model) freely available for anyone to download and run on their own hardware. Oddly, it’s the Chinese promoting free access to their most intelligent models, while all major U.S.-based AI labs continue their closed and secretive nature. We see this as problematic from multiple standpoints. First, frontier labs are making a bet that their models can consistently outrun the open-source ecosystem, which requires continuously higher spending levels. How defensible is this strategy if open source is always six to nine months behind? What if progress stalls and more money doesn’t always equate to breakthroughs? This lack of a competitive moat poses a threat to the likes of OpenAI, rather than the hyperscalers supplying compute access. Though, as we have hopefully made clear, OpenAI is at the center of this entire house of cards.
Too Big to Fail 2.0? ⛔
We believe it is not an understatement to assert that the ability for the AI datacenter buildout to earn a reasonable return on investment will define the next five years of S&P 500 returns. Fervor for AI, combined with the passive investment phenomenon (a pseudo momentum machine we have written about in past posts), has led to the Magnificent 7 accounting for 35% of the index, and we count 47% associated with the AI datacenter buildout theme. These figures jump to 45% and 59% respectively when discussing the Nasdaq 100. Perhaps more frightening, JP Morgan Asset Management found that AI-related stocks have accounted for 75% of S&P 500 returns, 80% of earnings growth, and 90% of capital spending growth since the launch of ChatGPT in November 2022.
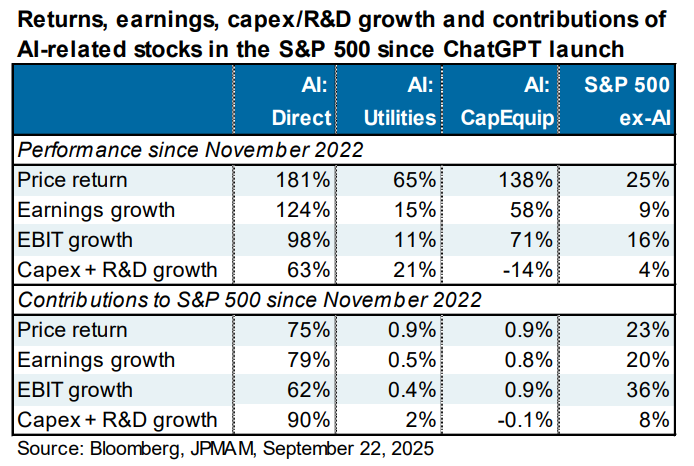 For Illustrative Purposes Only
For Illustrative Purposes OnlyAccording to Harvard Economist Jason Furman, the direct economic impact of the AI data center buildout contributed to 92% of GDP growth in the first half of 2025, meaning Real GDP would have grown at just 0.10%, excluding AI. We believe the indirect economic impact through the “wealth effect” is even greater. As we have expressed in previous posts, the stock market is no longer a reflection of the economy, but rather a determinant. Americans have enjoyed their wealth in both equities and real estate compounding at 13.3% and 8.3%, respectively per year since 2020 – in both cases nearly twice the long-term average. This has a tremendously positive impact on consumer confidence and, subsequently, consumer spending, which accounts for nearly 70% of the U.S. economy. Given the incredibly proportion of index gains attributable to AI, we believe it is no exaggeration to state AI has kept the U.S. economy out of recession. This naturally leads to the sobering possibility of the AI bubble “popping”.
Is it really a bubble? Most investors, both bulls and bears, will not hesitate to call it such, but with differing opinions on its life expectancy. With the cyclically adjusted S&P 500 price-to-earnings ratio in the 99th percentile, it’s hard to argue the point. A common thread across many historical major technological innovations is expectations of the speed of progress and rate of adoption often outpace reality, leading to an overbuilding of capacity. Shortages transition to gluts, and the oversupply drives prices down, which implodes the ROI equation. Even secular growth industries face natural cycles of increased demand, followed by large investment cycles, followed by oversupply, followed by price collapse. Despite its magnificent secular growth since the turn of the century, the semiconductor industry has faced multiple down cycles. The impact on share prices can be dramatic, as earnings not only decline, but so does the earnings multiple and often from an inflated level. For example, Nvidia’s stock has experienced peak-to-trough drawdowns of over 50% on five occasions since 2000, averaging 73%. The double whammy effect of a 20% earnings decline and an earnings multiple retreating from the 99th percentile to the 50th percentile can make for some waterfall charts.
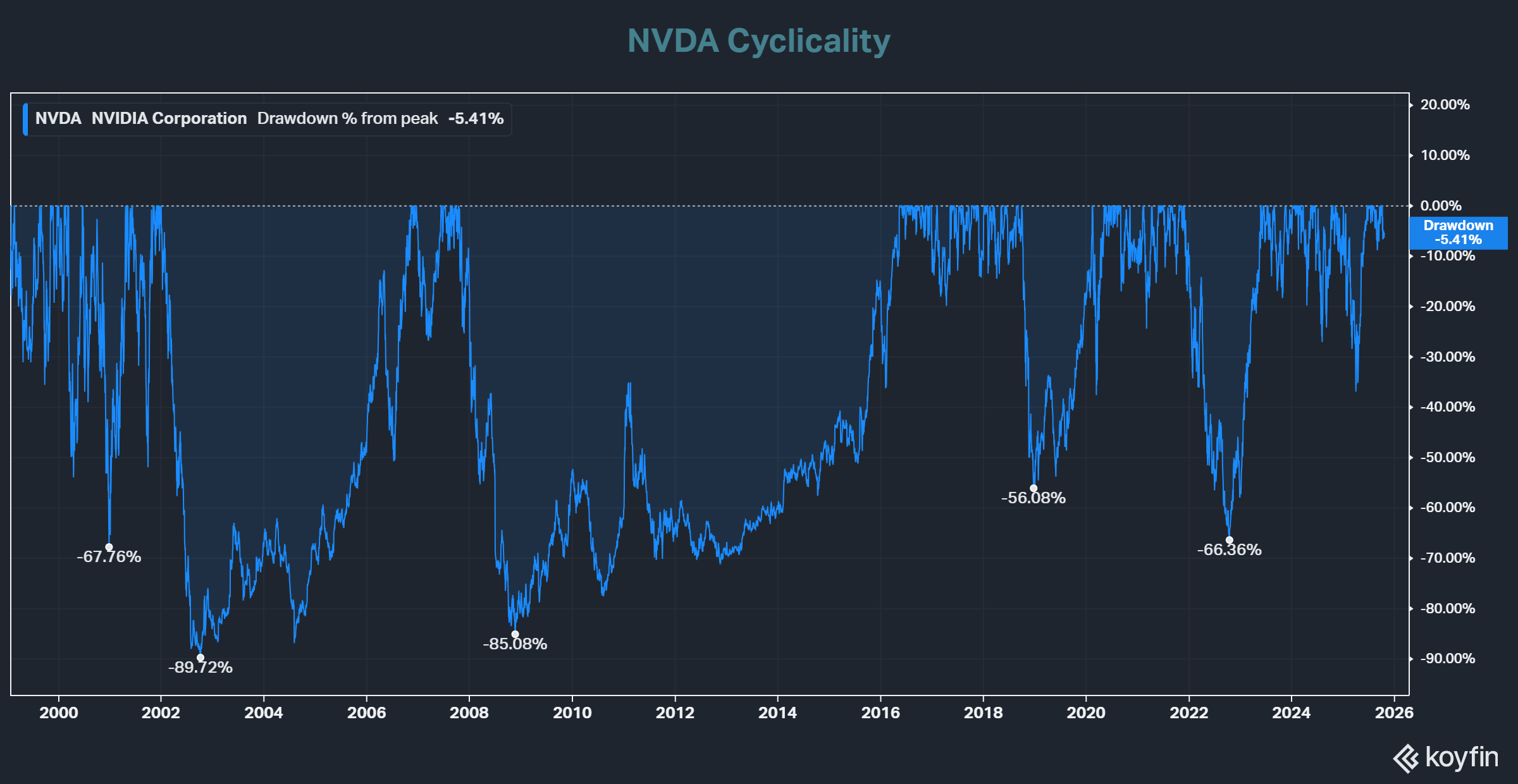 For Illustrative Purposes Only
For Illustrative Purposes OnlyIn our view, the most frightening aspect is that this bubble is core to the economy, whereas the dot-com bubble was largely on the periphery. Are we gambling the economy on scaling laws? Meanwhile, top researchers in the field, including Andrej Karpathy (former Tesla), Francis Chollet (former Google), and Yann LeCun (META Chief AI Scientist), all continue to reiterate that the current architecture of LLMs (Generative Pre-trained Transformers) is not capable of Artificial General Intelligence due to fundamental architectural flaws. They believe LLMs are not intelligent but rather feign it thanks to impressive pattern matching and regurgitation of all human text on the internet. In other words, they have access to immense knowledge but lack the ability to apply it via critical thinking. If we are hurtling down the wrong architectural path, how long will it take to correct course?
Let us not forget we are amidst a cold war with China. The race to superintelligence is a key frontier between the superpowers, and China has two cards that can slow U.S. progress. They appear to have just played the first, which is to restrict rare earth exports. Rare earth metals are crucial inputs for semiconductors, and while they are not actually rare in the Earth’s surface, refining capacity is indeed rare, with China home to 85% of it. While the U.S. is already taking aggressive steps to loosen China’s grip on rare earths, developing a formidable supply chain will take many years. Secondly, the small but increasing probability that China invades Taiwan is an ace up their sleeve in the AI race, as Taiwan is home to production of 92% of the world’s advanced chips – a frightening statistic and hands down the top black swan catalyst for bursting this bubble.
The trouble with bubbles is timing them. In some sense, “as long as the music is playing, you’ve got to get up and dance”. If history is any guide, the road to the top (if it’s still ahead of us) will be plagued with volatility – the Nasdaq’s dot-com era 366% run from 1998 to the peak in March 2000 came with eight peak-to-trough corrections of 10% or more, averaging 13.5%. Part of the difficulty is investors will not be able to appropriately judge today’s investments for several years, given the delay in building data centers, training models and preparing them for public release. If Sam Altman continues to convince people of his completely insane 250GW dream – well, then we may only just be getting started.
We suggest investors “dance” toward the exit, lightening exposure with each leg higher. As we’ve hopefully outlined, there are more than a few very compelling questions marks relative to the amount of capital being spent. However, in today’s narrative driven market, fundamentals are an afterthought to momentum. As Benjamin Graham famously said, “in the short run, the market is a voting machine, but in the long run, it is a weighing machine”. We believe the ROI math will be weighed heavily in due time. The good news is that if we are correct that the industry is overbuilding capacity, then access to AI will become cheap and plentiful and there will be plenty of exciting opportunities to invest in companies effectively utilizing AI in the same way that the dot-com era’s excess fiber capacity sowed the seeds of success for today’s internet giants.
Disclaimers
The information provided is for educational and informational purposes only and does not constitute investment advice and it should not be relied on as such. It should not be considered a solicitation to buy or an offer to sell a security. It does not take into account any investor's particular investment objectives, strategies, tax status, or investment horizon. You should consult your attorney or tax advisor.
The views expressed in this commentary are subject to change based on market and other conditions. These documents may contain certain statements that may be deemed forward‐looking statements. Please note that any such statements are not guarantees of any future performance and actual results or developments may differ materially from those projected. Any projections, market outlooks, or estimates are based upon certain assumptions and should not be construed as indicative of actual events that will occur.
All information has been obtained from sources believed to be reliable, but its accuracy is not guaranteed. There is no representation or warranty as to the current accuracy, reliability, or completeness of, nor liability for, decisions based on such information, and it should not be relied on as such.
Investments involving Bitcoin present unique risks. Consider these risks when evaluating investments involving Bitcoin:
- Not insured. While securities accounts at U.S. brokerage firms are often insured by the Securities Investor Protection Corporation (SIPC) and bank accounts at U.S. banks are often insured by the Federal Deposit Insurance Corporation (FDIC), bitcoins held in a digital wallet or Bitcoin exchange currently do not have similar protections.
- History of volatility. The exchange rate of Bitcoin historically has been very volatile and the exchange rate of Bitcoin could drastically decline. For example, the exchange rate of Bitcoin has dropped more than 50% in a single day. Bitcoin-related investments may be affected by such volatility.
- Government regulation. Bitcoins are not legal tender. Federal, state or foreign governments may restrict the use and exchange of Bitcoin.
- Security concerns. Bitcoin exchanges may stop operating or permanently shut down due to fraud, technical glitches, hackers or malware. Bitcoins also may be stolen by hackers.
- New and developing. As a recent invention, Bitcoin does not have an established track record of credibility and trust. Bitcoin and other virtual currencies are evolving.
No investment strategy or risk management technique can guarantee returns or eliminate risk in any market environment. All investments include a risk of loss that clients should be prepared to bear. The principal risks of Lane Generational strategies are disclosed in the publicly available Form ADV Part 2A.
This report is the intellectual property of Lane Generational, LLC, and may not be reproduced, distributed, or published by any person for any purpose without Lane Generational, LLC’s prior written consent.
For additional information and disclosures, please see our disclosure page.
Sources:
All financial data is sourced from Refinitiv Data or Federal Reserve Economic Data (FRED) unless otherwise noted.